内存数据局部性(Data Locality)
这其实是《Game Programming Patterns》中的一篇文章,它主要讲述了数据在内存中的布局是如何影响CPU缓存(CPU Caching),进而让程序性能产生巨大变化的。作者还没有写完,我就一直在关注这本书,这里面的大部分文章都值得一看,比如《Game Loop》,但这次先只翻译一篇。
Herb Sutter的演讲和Scott Meyer的演讲都提到了CPU缓存对性能提升的重要性,并且Herb还专门提到了《Data Locality》这篇文章,还用了这篇文章的数据作为论据,这促使我决定马上把它整理成中文了。
目标
将数据布局设置得和CPU更亲和,以提高内存访问速度。
动因
摩尔定律给我们的印象是,CPU的速度一直在增长,似乎程序员连指头都不用动一下,程序的效率也会自然而然地提高。呃,芯片的频率确实一直在提高(其实CPU的频率也基本限制在10GHz的数量级,这值得我另写一篇文章了),但这只是代表我们处理数据的速度越来越快了,但我们获取数据的速度就没那么快了。
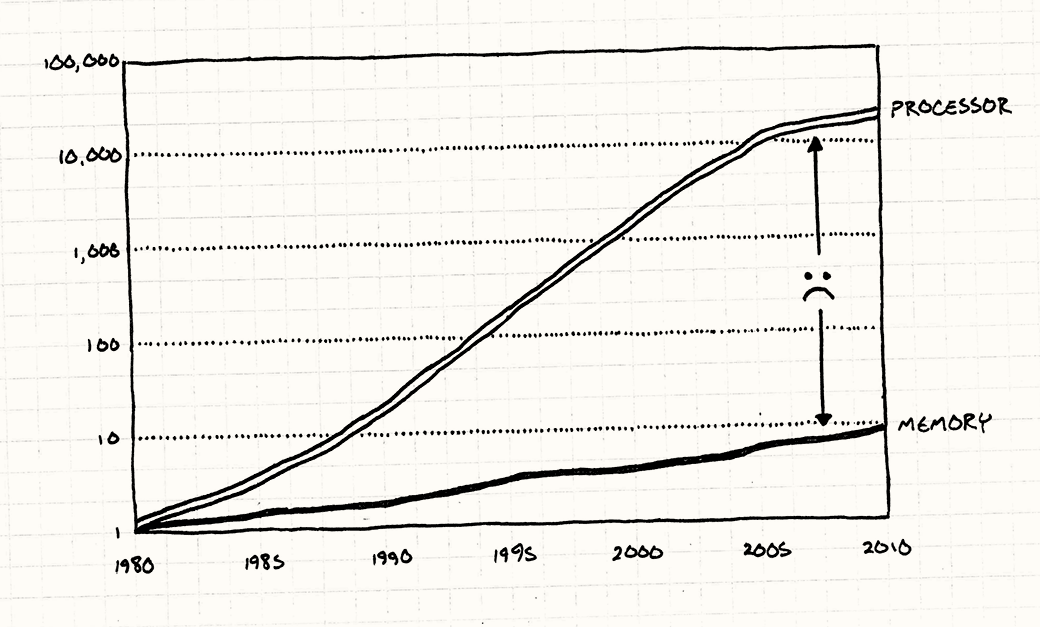
虽然你的牛X的CPU能够在短时间内做大量的数据运算,但也得先把数据从内存中读出来,倒到寄存器里面去才行。然而,上面的图就说明了内存的读写速度被CPU甩好几条大街了。当今的硬件环境下,从内存中读取一个字节的数据需要花好几百个时钟周期,假设大多数指令都需要花几百个时钟周期来获取数据,那我们的CPU如何不会浪费99%的时间在等待数据上?实际上,CPU确实有大量的时间是堵在等待内存数据上,但是情况也不是那么坏,下面我们开始用一个比喻来说明这个情况。
数据仓库
假设你是一个小办公室里的会计师,你的工作就是拿到一盒子文件,然后根据这一盒子文件做一些加加减减的会计工作。当然,你是根据一些只有会计师才懂的神奇逻辑来指定要拿那个盒子的文件的。由于你的勤奋努力、天资聪颖或者其他的什么原因,你能够在一分钟之内处理完一盒子文件。但是,还有一个小问题,所有那些装文件的盒子都存放在另一栋楼里的一个仓库中。要拿到文件盒子,你只能请仓库管理员送过来给你——他会开着一辆叉车在堆积如山的仓库中慢慢转,直到找到你要的那盒文件。这得花上他一整天的时间来拿到你要的文件盒。不像你,他没什么希望获得月度优秀员工的称号。这意味着无论你的速度有多快,你一天只能处理一个盒子的文件,剩下的时间里,你只能坐着思考人生。
直到有一天,一波搞工业设计的人出现了,他们的工作就是提高效率,比如让流水线走得更快之类的。他们在观察了你好几天之后,发现了一些特点:
- 很多情况下,当你处理完一盒子文件后,你需要的下一个盒子也就在仓库中当前盒子的旁边。
- 用一个叉车来运送仅仅一个盒子的文件实在有些浪费。
- 你的办公室的角落其实还是有一点多余的空间的。
他们想出了一个很聪明的解决方案:每次你让仓库管理员给你去一盒文件时,他除了取回你指定的之外,还把旁边一整排文件盒子都给你送过来,他不知道你是否需要那些盒子的文件(鉴于他的工作积极性,他其实也不关心),他只是把尽可能多的文件盒子放到叉车上给你送过来,放到你办公室的角落里。
当你在找下一个文件盒子的时候,你首先要做的是看一看它在不在你办公室角落的那一对盒子中。如果在它在里面就好办了,你只需要花一秒钟的时间把那个盒子搬到桌子上,然后就可以继续你的加加减减了。如果办公室角落那里可以堆50个盒子,并且碰巧所有你需要的盒子都在这个盒子堆里,你的工作效率将提高50倍!
但是,如果你需要的文件盒不在那一排里面,那你就回到原点了。因为你的办公室职能放得下一排盒子而已,仓库管理员只能先把你办公室的盒子先运回去,然后再给你送一排新的过来。
给CPU用的一排盒子
凑巧的是,这与现代的CPU的工作方式十分相似。可以想象,你来扮演CPU的角色,你的办公桌就是CPU的寄存器,一盒子文件就是刚好能装满寄存器的数据,仓库就是你的内存,那个烦人的仓库管理员就是从内存往寄存器取数据的总线。
如果我(指作者,译者这时候还没出生)是30年前写这篇文章,比喻就到此为止了。但随着处理器越来越快,而内存却没有跟上,硬件工程师们就开始寻找解决方案了,比如说,CPU缓存。
现代计算机的芯片上有一小片缓存,CPU从这里读数据会比从内存中读数据要快得多。这片缓存之所以设置得很小,一方面是因为要集成到芯片上,另一方面,是因为这种类型的缓存(SRAM)比内存(RAM)贵多了(RAM里面的一个比特其实就是一个电容,而SRAM里面的一个比特是由4到6个三极管组成的电路保存的——译者注)。
这一小片存储空间就是缓存(Cache),而直接集成到芯片上那一小部分就是一级缓存(L1 Cache)。在上面的类比中,就是那一排文件盒子。每当你的芯片需要从内存读取哪怕一个字节的数据,一段连续的内存就会被读进来(一般是64~128字节)并放入缓存中。这用来放一排文件盒子的地方,就叫一个缓存行(Cache line)。
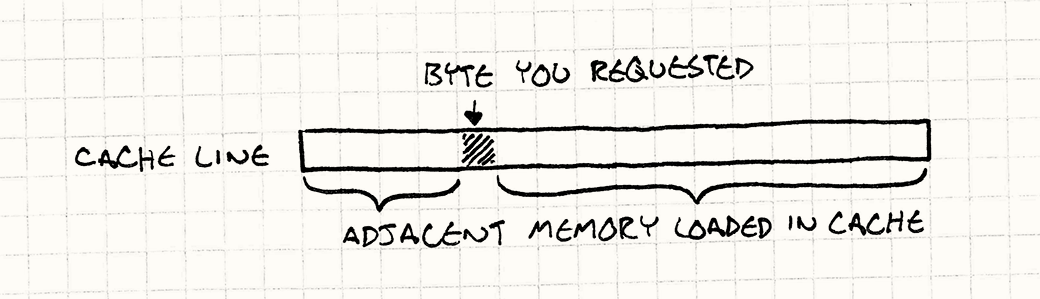
如果你需要的下一个字节数据刚好在这个缓存行中,那CPU就可以直接从缓存行中读出来,这比从内存中读取快多了。成功地从缓存中找到数据叫作Cache hit,缓存中找不到而需要去内存中找的时候就叫作Cache miss。
出现cache miss之后,CPU就只能停下来,无聊地等了好几百个时钟周期之后,数据终于从内存里面读进来,它才能执行下一条指令。当然我们的任务就是避免这种情况的发生啦。试想如果你要优化下面这样一段影响性能的关键代码:
for (int i = 0; i < NUM_THINGS; i++)
{
sleepFor500Cycles();
things[i].doStuff();
}
你准备做的第一件事情是什么?对,删掉那个没有意义有沉重的sleep函数调用。那个函数调用对性能的损耗和一次cache miss是一样的,所以你每次从内存读数据的时候,你就像是加了一行sleep这样的延时代码一样。
且慢,数据就是性能?
当我(作者)开始准备这一章的内容时,我写了一个用来触发最优条件和最差条件的小程序,我非常想亲眼看看缓存猛烈抖动的时候是怎样的一个惨烈。
结果出来之后,我吃了一斤。我预料到缓存抖动是个大事儿,但亲眼看见的感觉完全不一样。我写了两个几乎完全一样的程序,唯一的区别就是它们会引发不同程度的cache miss,而慢的那个比另一个慢了50倍。
这简直让我大开了眼界,我曾以为性能就是代码的事,而不是数据的事。一个字节并没有快慢之分吧,它只是一个静态的东西而已,但是有了缓存,数据的分布就会大大地影响性能了。
现在要做的就是怎么把上面的东西揉成一个章节了。缓存优化是一个很大的课题,我还没说到指令缓存,别忘了,内存中的代码也是要接在到CPU中才能执行的。这个课题值得一些专家写一整本书了。
既然你已经在看我这篇文章,我就告诉你几个基本原则,让你可以开始思考数据结构是如何影响你的程序性能的。说到底其实很简单:每当CPU要读取内存的时候,它会读取一整个cache line,你能把越多你可能用到的数据挤到这个cache line里面,你就跑得更快。于是,我的目标就是,组织好你的数据结构,使你要处理的内容在内存中是相邻的。
换句话说,如果你的代码要处理A,然后B,然后C,那你最好让它们在内存中的布局是这样的:
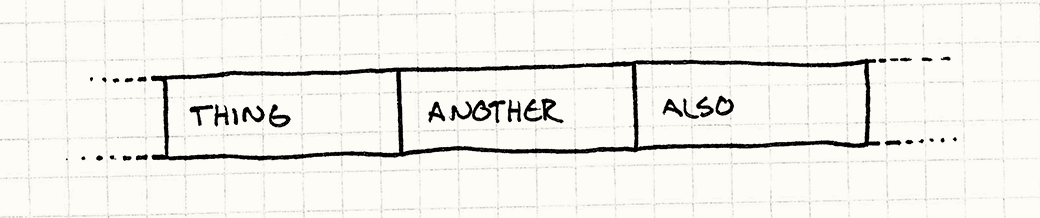
需要指出的是,这里的A、B、C课不是指向数据的指针,而就是它们自己,一个接一个地排在一起。一旦CPU要读A,它就会把B和C也读进去(当然这取决于A、B、C有多大,以及cache line有多大),当CPU开始处理B的时候,B已经在缓存里了,皆大欢喜啊!
模式
现代CPU使用缓存来加速内存访问,所以访问刚访问内容旁边的内容的速度会快很多。提高数据局部性——让数据按照你要处理它们的顺序排列以提高内存访问速度。
什么时候该用这个模式呢?
和大多数优化一样,首要的原则是,当你真的遇到了性能问题的时候,才考虑优化它。不经常执行到的代码就不要浪费时间优化了。没必要的时候进行优化只会让你的生活更苦逼,因为那样几乎一定会导致代码复杂化和不灵活。
具体到这个模式,你还必须确认你的性能问题的确是由cache miss引起的,如果你的代码是因为其他原因跑得慢,这个模式帮不了你。
简单的方式是手动加一下监控代码,看看两个代码点之间究竟花了多长时间,可能你需要一个精确一点的计时器。要捕获cache miss,你还需要一些更复杂的工具,因为你真的需要了解你的程序会在哪里、发生多少cache miss。
幸运的是,外边已经有很多工具可以做这个事情了,花点时间倒腾其中一个,并且确保你明白它输出的一大堆数据是什么意思,你再开始对你的代码开刀吧。
我只是说,cache miss会影响程序的性能,但你也不应该花大量时间做超前的缓存优化,当然,设计的时候尽可能地考虑缓存亲和性还是必要的。
注意
软件架构的一个主要特点就是抽象化,本书(指Game Programming Patterns)的一大部分也是在讲如何解构各部分代码,以便使它们更方便各自更新。在面向对象语言中,这基本上就意味着接口。
在C++中,使用接口就意味着通过指针或者引用访问对象。但是使用指针就意味着在内存中跳来跳去,导致本篇文章要避免的cache miss问题。
为了满足这个模式,你得牺牲一些代码的抽象性。你为你的程序做的数据局部性越多,你就得放弃更多的继承和接口,以及那些工具带给你的便利。天下没有十全十美的解决方案,就看你怎么取舍了,当然这也正是乐趣所在。
样例代码
如果你一定要走上数据局部性优化这条不归路,好吧,你会发现无数种方式来切分你的数据,以便你的CPU能更容易处理它们。作为开始,每一种常见的组织数据方式我都会用一个例子来说明,我的例子会以一个游戏引擎为背景,但注意背后的基本技术是可以应用到其他地方的。
连续数据
让我们从一个处理大量实体的游戏循环开始吧。这些实体根据领域被分解成了不同的部分——AI,物理模块,渲染模块,比如这样:
class GameEntity
{
public:
GameEntity(AIComponent* ai,
PhysicsComponent* physics,
RenderComponent* render)
: ai_(ai), physics_(physics), render_(render)
{}
AIComponent* ai(){return ai_;}
PhysicsComponent* physics(){return physics_;}
RenderComponent* render(){return render_;}
private:
AIComponent* ai_;
PhysicsComponent* physics_;
RenderComponent* render_;
};
每种组件都只有一组相当少的状态,可能是几个向量或者矩阵,以及一个更新它的函数。它内部的细节并不重要,只要想象大概是这样的就好了:
class AIComponent
{
public:
void update(){/* Work with and modify state... */}
private:
//Goals, mood, etc. ...
};
class PhysicsComponent
{
public:
void update(){/* Work with and modify state... */}
private:
//Rigid body, velocity, mass, etc. ...
};
class RenderComponent
{
public:
void render(){/* Work with and modify state...*/}
private:
//Mesh, textures, shaders, etc. ...
};
游戏维护了一个巨大的指向虚拟世界中各个实体的指针数组。游戏循环的每一轮运转,我们都要顺序执行下面的步骤:
- 更新所有实体的AI组件。
- 更新所有实体的物理组件。
- 通过它们的渲染组件渲染它们。
很多游戏引擎都是这样来做的:
while (!gameOver)
{
// Process AI.
for (int i = 0; i < numEntities; i++)
{
entities[i]->ai()->update();
}
// Update physics.
for (int i = 0; i < numEntities; i++)
{
entities[i]->physics()->update();
}
// Draw to screen.
for (int i = 0; i < numEntities; i++)
{
entities[i]->render()->render();
}
// Ohter game loop machinery for timing...
}
在你没有听说CPU缓存之前,上面的代码看起来似乎没什么问题。但现在,你回隐隐约约感觉到有点不对劲了。这代码不仅是在抖动缓存,它简直是在来来回回把缓存搞成浆糊了。看看它都做了什么:
- 游戏实体的数组是一个指向实体的指针,所以对于数组的每一个元素,我们都得提领指针,这是一个cache miss。
- 然后游戏实体还有一个指向组件的指针,这又是一个cache miss。
- 然后我们调用组件的更新函数。
- 现在我们回到步骤一,对每一个实体的每一个组件重复一次。
可怕的是,我们根本不知道这些对象在内存中是怎么分布的,而只能听凭内存管理器的发落了。因为实体不断地被分配,一段时间之后被销毁,堆内存很可能变成很随机的分布了。
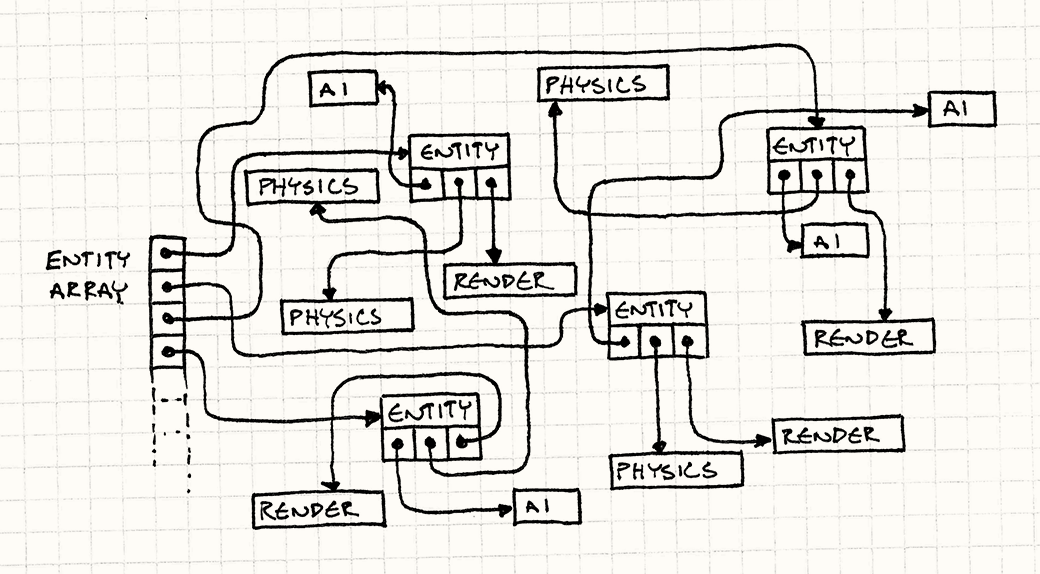
如果我们的目的是在游戏地址空间里来一个类似“256M内存4日游”之类的廉价旅游套餐,这倒是个不错的选择。可惜我们的目的是让游戏跑得更快,而在内存里面到处闲逛显然不是一种好方法。还记得sleepFor500Cycles()函数吧?这段代码简直就是在不断地调用这个函数。
好吧,让我们把代码改得好一点吧。首先可以观察到,我们通过指针来获取游戏实体的唯一原因是,我们可以马上访问下一个实体的指针。游戏实体本身并没有什么有意思的状态,或者有用的函数,它内部的组件才是游戏循环关心的。
与其在地址空间这个漆黑夜空中撒上无数繁星点点的游戏实体和组件,我们还是回到地球上来吧。我们为每种组件维护一个巨大的数组:AI组件、物理组件和渲染组件各自一个普通的数组。比如这样:
AIComponent* aiComponents = new AIComponent[MAX_ENTITIES];
PhysicsComponent* physicsComponents = new PhysicsComponent[MAX_ENTITIES];
RenderComponent* renderComponents = new RenderComponent[MAX_ENTITIES];
我要再说一次,这些是组建的数组,不是指向组件的指针数组。数据一个字节接一个字节地就在那儿了。游戏循环可以直接这样访问了:
while (!gameOver)
{
// Process AI.
for (int i = 0; i < numEntities; i++)
{
aiComponents[i].update();
}
// Update physics.
for (inti = 0; i < numEntities; i++)
{
physicsComponents[i].update();
}
// Draw to screen
for (int i = 0; i < numEntities; i++)
{
renderComponents[i].render();
}
Other game loop machinery for timing...
}
我们丢弃了所有那些指针跳转,不再在内存里面跳来跳去,而是直接在3个连续数组爬过去就可以了。
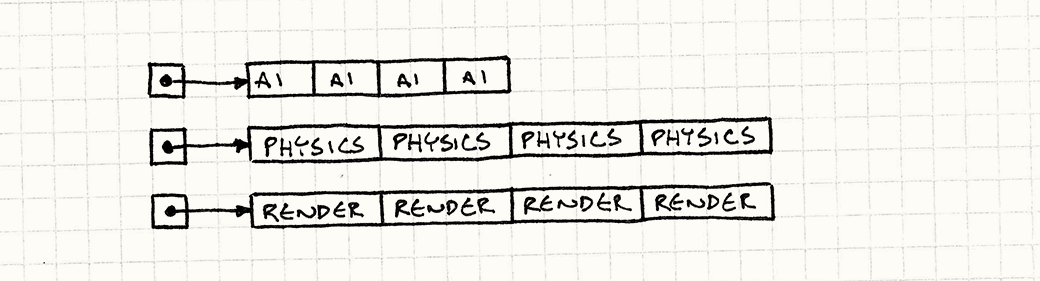
这样我们把一个稳定字节流直接放到CPU饥饿的嘴巴里去了。在我的测试中,这个修改可以让整个循环比原来快50倍。
有趣的是,我们并没有丢失很多封装性。的确,游戏循环现在直接就更新各个组件,而不是通过游戏实体来更新了,但我们之前那样也只是为了保证能按照正确的顺序处理它们而已。即使是现在这样,每个组件本身还是得到了良好的封装性,它拥有自己的方法,我们只是修改了它调用方法的方式。
这个修改并不意味着我们也需要丢弃游戏实体这个类。我们可以就像以前那样保留指向其组件的指针,只是它们现在会指向那些数组而已。这样,当你想向游戏的其他模块传递游戏实体这个概念时,所有的内容都会跟过去。重要的是,影响性能的关键部分已经直接访问到数据了。
(未完待续,文中的图片链接也是Bob Nystrom个人网站上的)